Generative AI has become a ubiquitous topic in recent times, especially after Large Language Models (LLMs) and other AI brands made it to the spotlight through public discourse. These LLMs and other AI-powered applications can be used for various reasons and leveraged effectively for individual applications or industrial purposes.
While generative AI has profound uses in various domains, a few roadblocks do occur when training models with your data to provide appropriate answers. LLMs built for mainstream applications or general purposes can be trained with readily available data from numerous sources across the internet. But they are rendered ineffective when an in-depth request is made relating to a particular company, industry, or software.
Just like this example below:
 Asking about Soliton’s Recognition Policy to LLM
Asking about Soliton’s Recognition Policy to LLM
In this scenario, the query posed to the LLM regarding the company’s internal data returns an incorrect answer. With further prompting, it can provide answers to the user’s request in the best way possible, though it might not be accurate.
Focusing on usage within hi-tech companies, especially the semiconductor industry, the challenges in training generative AI models with the organization’s private data need to be addressed.
In this blog, let us delve deeper into the challenges associated with generative AI and the potential means for semiconductor companies to harness its power with private data.
Challenges with Data Security
One of the primary challenges in any industry, including semiconductors, when considering generative AI is the importance of “Data Security.” These industries possess invaluable data and intellectual properties that they are unwilling to jeopardize by employing them to train a public LLM. Selecting an effective model, while not compromising on data security is crucial.
There are two main approaches when selecting a model:
- Service-Based Models: These models are offered by vendors on a pay-as-you-go basis. The training data and model are not accessible by end users, and the interaction with the model is limited to queries. This approach is suitable for companies that are comfortable with the model provider’s data security policies.
- Internally Hosted Models: If the company chooses to have more control over its data and is not entirely convinced about security policies offered by external vendors, it can choose to host their LLMs internally. They might choose to build a model from scratch or choose an appropriate model from multiple marketplaces (for example, Llama 2). This provides greater control and ensures that data security policies are tailored to the company’s specific needs.
While security aspects can be addressed with internally hosted models, service-based models also offer value in terms of the service they provide. Some of the most powerful LLMs available currently are service-based models.
This leads to the next concern – how to train a service-based LLM with an organization’s private data?
Challenge of Hallucinations
Even after picking a suitable model that offers better data security, another intricate challenge is the risk of hallucinations.
Sometimes, the generative AI model or LLM might provide wrong information or fabricated answers to the user in a persuasive manner. This phenomenon is known as “hallucination” and is another obstacle when relying on generative AI. Hallucination of an AI model often feeds engineers with the wrong information, leading to erroneous decisions.
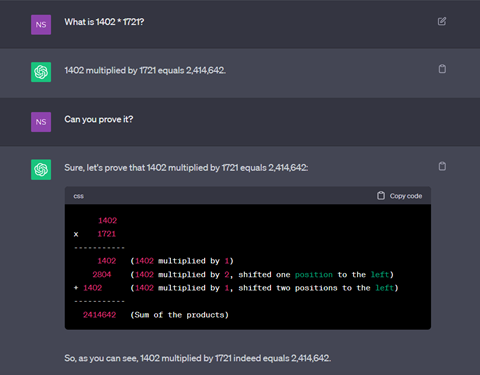 Example of LLM hallucinations
Example of LLM hallucinations
Here is an example of hallucination. When asked to multiply two values 1402 and 1721, the LLM provides a wrong answer confidently. It displays the value 2,414,642 and explains it, whereas the right answer is 2,412,842.
To mitigate the risk of hallucinations, it is important to ensure that the model uses the correct data for its answers
Challenge of Cost and Training
For industries with vast datasets, like the semiconductor industry, training and fine-tuning an LLM is a resource-intensive process involving several GPUs and hours to achieve optimal results. It even involves constant optimization along with trial-and-error methods to identify areas of improvement.
Sometimes, training and fine-tuning methods might be an overkill if the data and policies keep changing or updating perpetually. This requires the model to be trained and fine-tuned constantly, thereby making this training and fine-tuning process a futile approach.
The above describes significant challenges that companies need to solve before they can effectively leverage generative AI models, trained with private data to provide accurate answers for users.
The Solution: Retrieval Augmented Generation
Soliton highly recommends Retrieval Augmented Generation (RAG) for developing generative AI with private data in large organizations.
In any organization, most of the data is unstructured – it is data contained across spreadsheets, files, and folders within user systems, shared network drives or the cloud. Retrieval Augmented Generation allows for effective retrieval of the data from multiple such data sources (structured or unstructured), augmenting and summarizing the information to the user without training or fine-tuning the model.
How Does Retrieval Augmented Generation Work?
Retrieval Augmented Generation contrasts with the typical approach, which tries to ascertain the model’s answer after the user poses a question. The RAG process has 2 critical steps – “search” and “summarize” – before arriving at the solution.
- Search: Instead of relying on the LLM to answer when a query is posed, RAG combs through the private data it can access to acquire relevant information that can be used for preparing a response. This search is meaning-based and aims to find the information that can best help provide an answer to the query posed.
- Summarize: Once the relevant information is acquired, the LLM then generates a contextual answer by summarizing the retrieved data in a presentable manner.
The RAG method of providing the answer solves 2 critical challenges mentioned above – hallucination & training. It helps minimize hallucinations by grounding the LLM to summarize answers only based on retrieved data. Since data retrieval is done on the fly, based on the user questions, no training or pre-training is required.
This method allows us to avoid the need for pre-training the LLM. It also limits the use of LLM to summarize data that is presented to it on the fly, rather than having the LLMs possess implicit knowledge. Such use of LLMs can also ensure that service-based models can be an effective choice.
Here is an image showcasing the success of RAG:
 Using RAG, asking questions about internal data using Soliton Chatbot
Using RAG, asking questions about internal data using Soliton Chatbot
When posing a question relating to a company’s internal data, in this case, Soliton’s Recognition Framework, to Soliton Chatbot, the LLM is able to answer precisely with the help of Retrieval Augmentation Generation.
Better User Experience Options
LLMs or AI models can be implemented for a semiconductor company in several ways. Chatbots continue to remain a popular choice owing to their simplified interface and end-user experience. However, it is important to not be limited only to the usage of chatbots, but to explore other effective means by which generative AI models can be integrated into the workflow in order to provide the most effective end-user experience.
Your Answer to Internal Requests: RAG and LLM
Harnessing the power of generative AI opens a world of possibilities, providing immediate answers and efficient insights relating to the semiconductor industry. However, it comes with its share of challenges, primarily related to data security, hallucinations, and cost.
In our upcoming blogs, we will talk more about using RAG for private data and how we, Soliton, embraced innovative methods to build applications to provide accurate information based on insights from user data. We will also talk about using frameworks like LangChain and llamaIndex for RAG and ways to leverage them and about different options for optimizing results through RAG.
Stay tuned for more blogs to know more about how generative AI can be leveraged in your organization, and if you are looking for any help, please reach out to us at [email protected]