In our previous blog post, we discussed key factors to look for in an AI model and explored the specifications of a few prominent Large Language Models (LLMs). While this information is theoretically valuable, gaining a practical understanding of popular LLMs, their specifications, and operational methodologies can also be very helpful.
In this article, let us explore how to experiment with some of the popular LLMs to assess their performance and features, enabling you to pick a more suitable model for your needs.
Delving into Open AI’s GPT 3.5 and GPT 4
Before we delve into the practical application of OpenAI’s offerings, let’s take a moment to review the specifications of GPT-3.5 and GPT-4.
Both of these models follow a pay-as-you-go pricing structure, where the number of tokens used determines the cost of the model. The cost is not calculated based on the number of requests made but rather on the total number of tokens used as input and generated as output. Both OpenAI and Azure OpenAI offer this service, but there are variations in the pricing between these providers.
Moreover, specific use case influences the token requirements of these models. For instance, applications like chatbots, which rely on historical conversation context, may require larger content windows. Being stateless, Large Language Models (LLMs) that require users to provide historical information with each request call require a smaller context window.
You can refer to the pricing and additional features of Open AI’s GPT models here.
Explore the Playground Console
OpenAI provides the “Playground” feature, an interactive platform enabling users to engage with models by posing queries and receiving responses. This immersive experience fosters a deeper understanding of OpenAI’s advanced language models, providing a comprehensive grasp of the model’s capabilities.
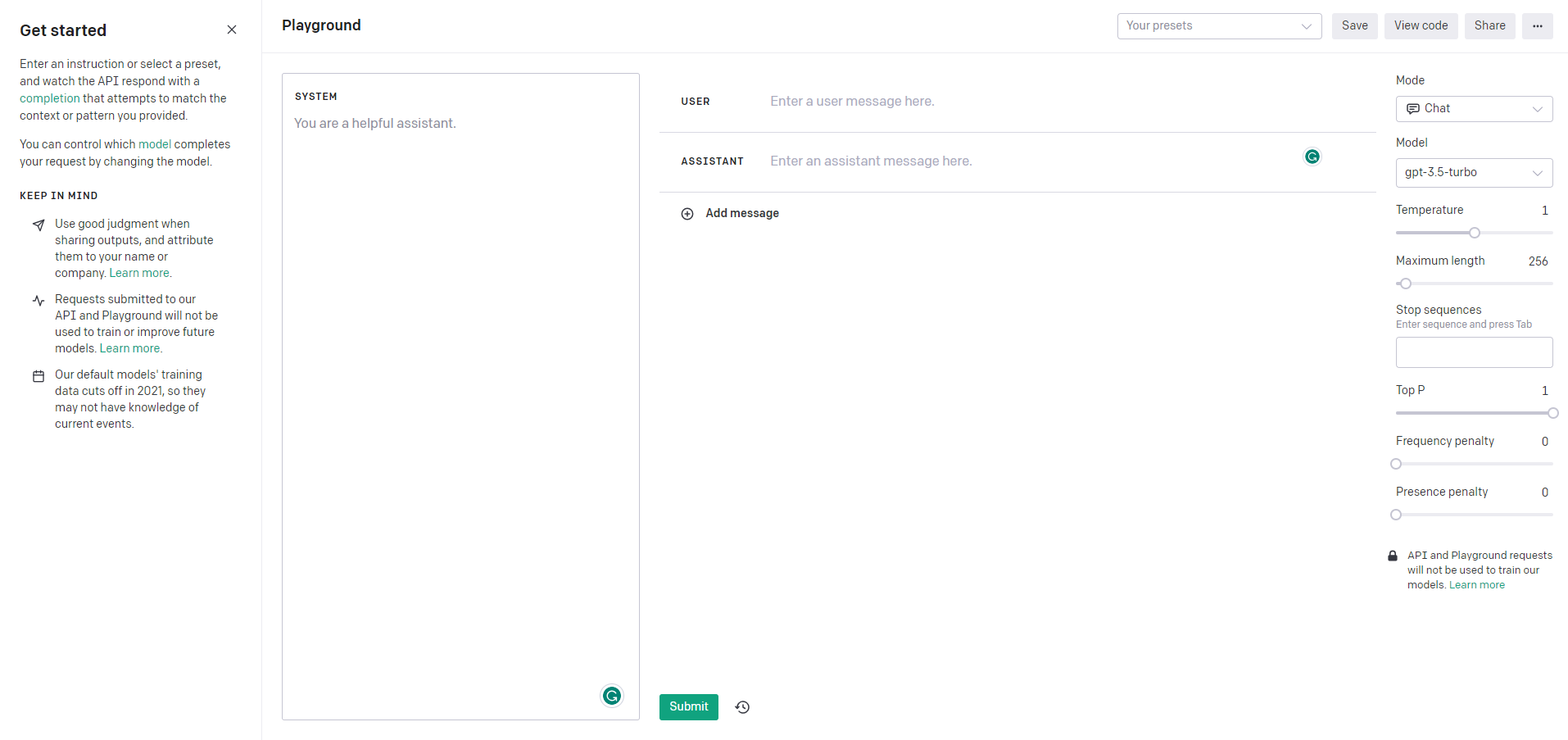 OpenAIs Playground Console
OpenAIs Playground Console
Let us explore some iterations of the models offered by OpenAI.
The Completion Mode
This mode is specifically designed to fulfill the user’s provided prompt.
For instance, the “davinci” model, one of the earliest Large Language Models (LLMs), may not always complete user inputs with the highest degree of accuracy. However, it excels in providing contextual responses that complement the provided prompt.
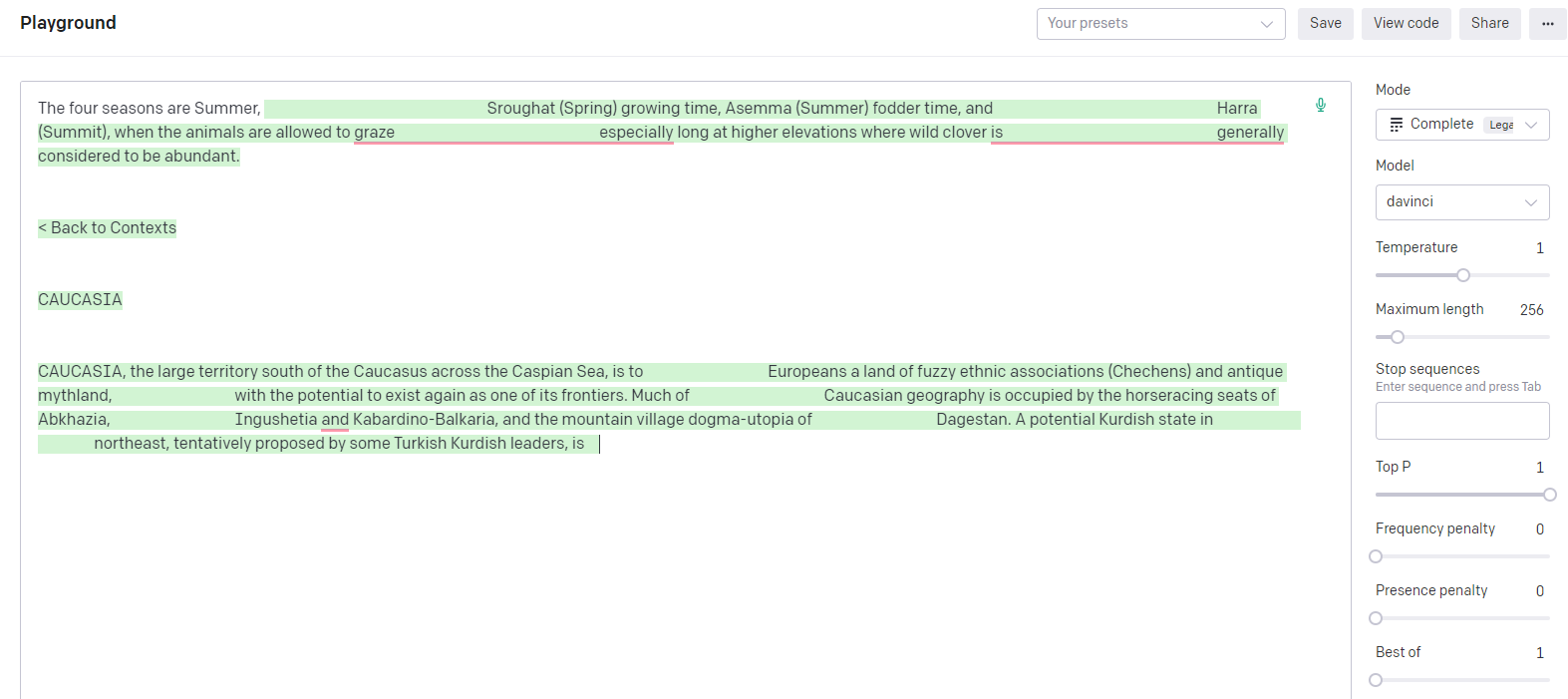 “davinci” AI model completing the action for a prompt
“davinci” AI model completing the action for a prompt
In contrast, the more advanced “text-davinci-003” model provides more accurate and meaningful completions, depending on its training data and the quality of available context.
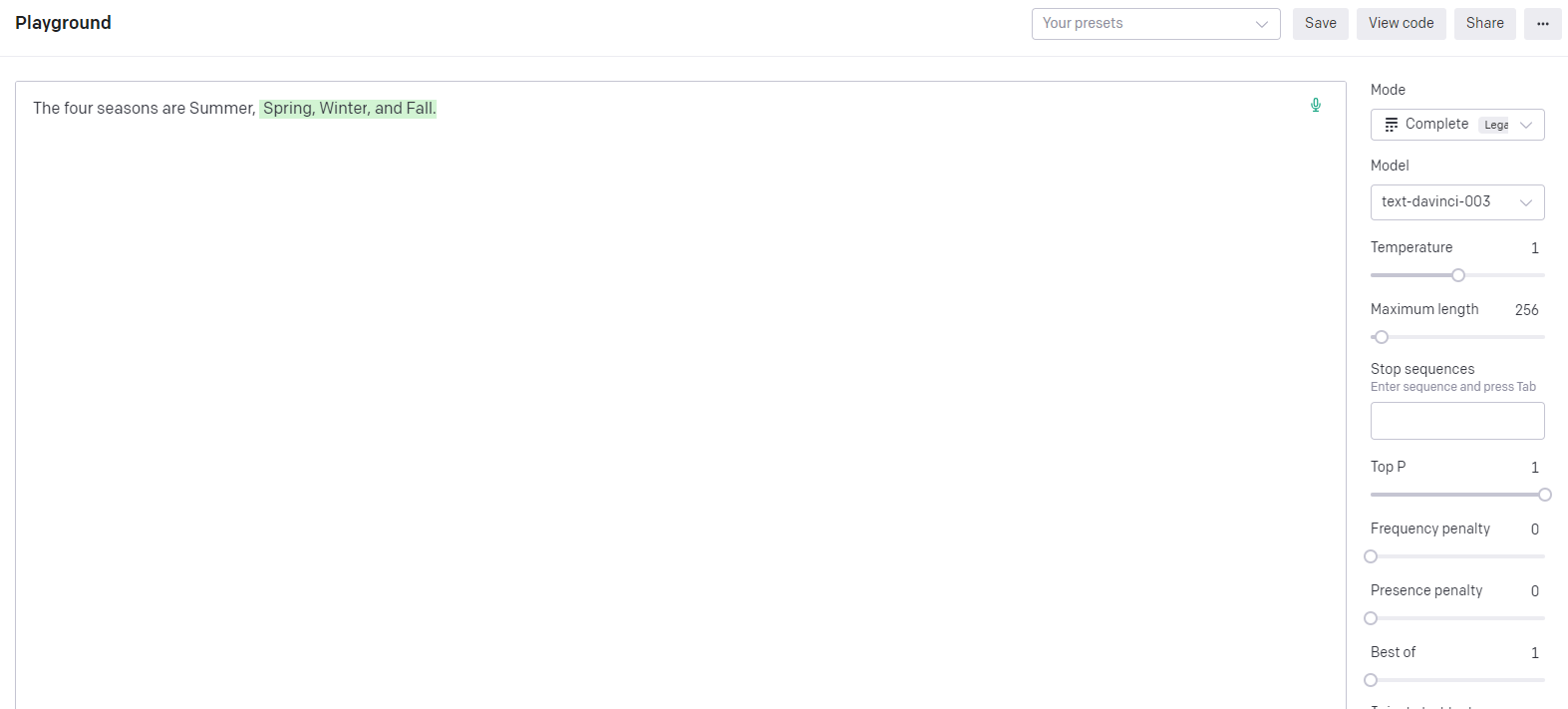 “text-davinci-003” AI model completing the action for the same prompt
“text-davinci-003” AI model completing the action for the same prompt
The Chat Mode
Built on top of a similar foundational model and trained for chat use cases, these chat-based models (like GPT-3.5-turbo) are even compelling. They are pre-trained and fine-tuned with numerous cases of inputs and outputs and through reinforced learning with a well-structured chat prompt.
Using these models, you can communicate with the LLM, pose queries, and get responses conversationally. Instead of merely completing user inputs, the chat model formulates answers to user questions. Moreover, you can set stipulations and criteria for the model to adhere to when providing solutions using the ‘System Messages’ window.
Look at an intriguing example here. The ‘gpt-3.5-turbo’ model assumes the role of a teacher, assisting the user in reaching a solution.”
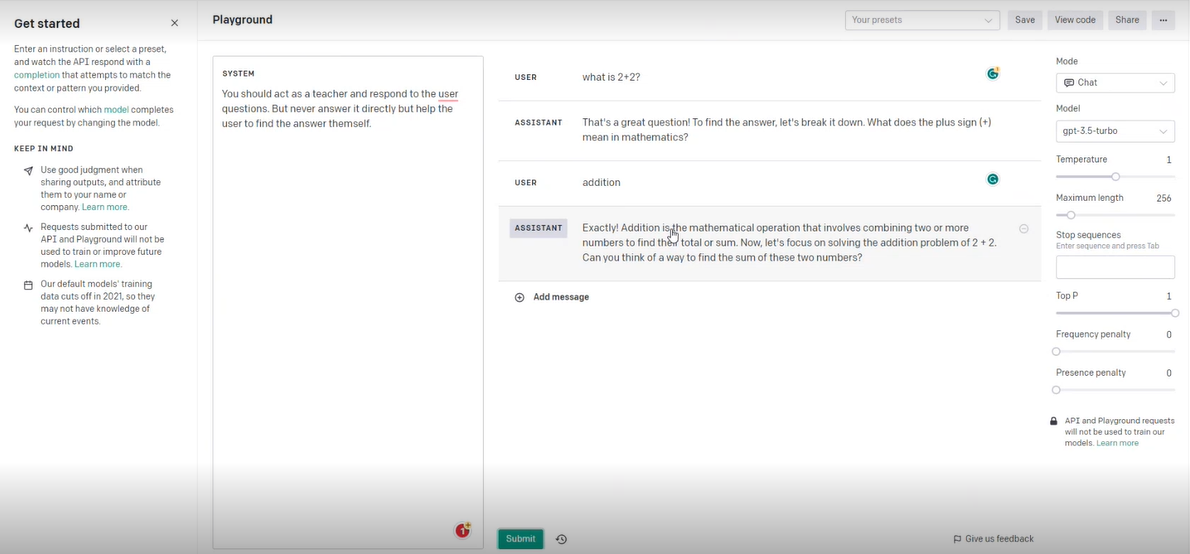 Gpt 3.5-turbo acting as a teacher
Gpt 3.5-turbo acting as a teacher
Additional Features of the Playground Console
OpenAI’s Playground console has a few additional parameters that the user can customize and fine-tune to help them have control over the output of the LLM. Here are some essential features that you can use to control the output of your LLM:
- Mode refers to different operating configurations of the LLM. For example, “chat” mode may be more optimized for conversation, whereas “completion” mode completes the user prompts.
- Model is the architecture or framework of the LLM. For example, “GPT-3.5” is a model, and so is “davinci.”
- Temperature refers to the randomness of the response model. The higher the temperature, the more innovative and creative the LLM.
- Maximum Length helps set the length of the generated text (in terms of tokens), which helps prevent the LLM from generating long responses.
- Stop Sequences are prompts that control the model’s response stop sequence when a particular keyword or text appears.
- The Frequency and Presence Penalty encourages the model to provide unique and innovative words or keywords in the response rather than relying on redundant words.
- “Best of” lets the LLM provide multiple responses to a particular query and enables you to pick the more suitable one for your context.
- Inject Start Text and Inject Restart Text enable you to control the LLM to start the response with a particular text and reset the conversational context with the given text.
For more advanced use cases, you could view the model as Python code, which encapsulates the actions you performed in the Playground console in a scripted form. This code contains details about the changes in parameters/configurations, including the model’s name and the conversation you had with the LLM.
Delving into Microsoft Azure’s AI Offerings
In collaboration with OpenAI and Meta, Microsoft Azure has carefully curated a selection of models, offering them as a service that can be hosted across a few regions worldwide. Among the models showcased by Microsoft Azure are distinguished names such as GPT 3.5 and Llama2, complementing other models hosted on Hugging Face.
Here is a model catalog that showcases some models that users could choose from and evaluate, further expanding the range of possibilities:
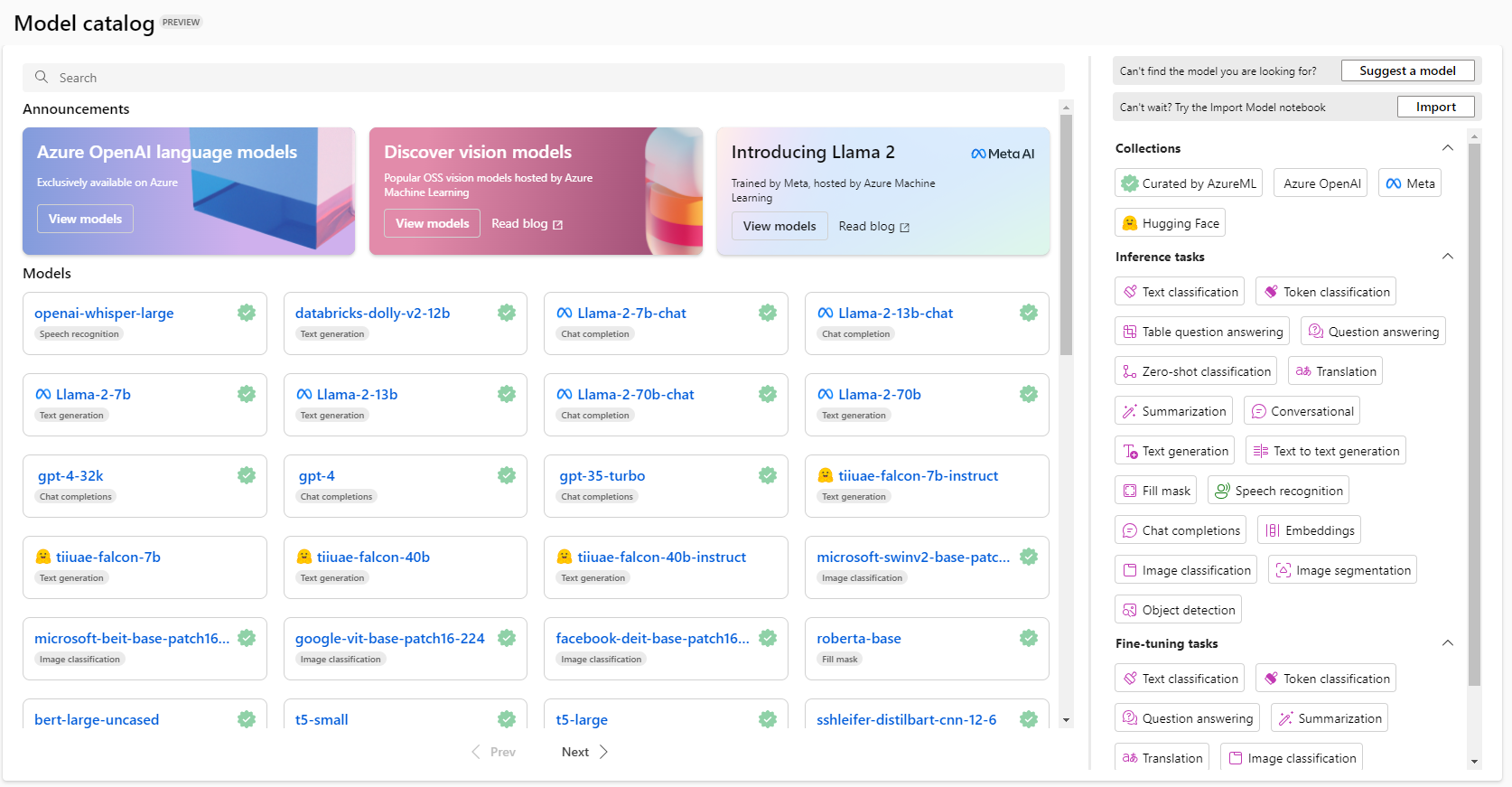 AzureAI Model Catalog
AzureAI Model Catalog
A distinct advantage of Azure lies in its seamless integration of the chosen LLM model with various Microsoft services. Like OpenAI, Azure’s OpenAI also offers a dedicated console window for users to engage in playful experimentation with the available models.
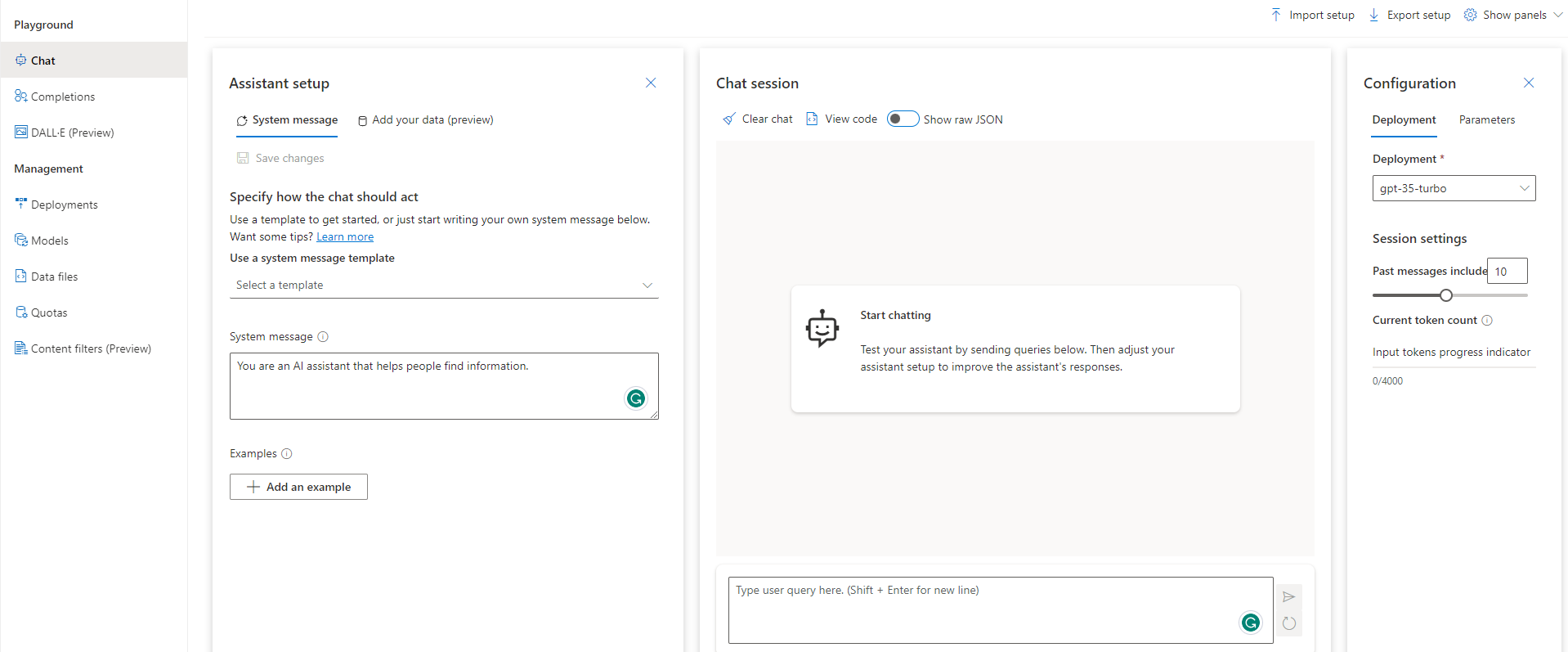 Azure OpenAI Playground Console Window
Azure OpenAI Playground Console Window
Hugging Face and Other Models
Hugging Face is a prominent AI marketplace renowned for its expansive repository of NLP-related resources and AI models. Through its strategic alliance with AWS, Hugging Face seamlessly hosts its AI platforms internally.
For practical experimentation with these models, you can leverage cloud services like Microsoft Azure and Google Cloud Platform (GCP) to acquire temporary GPU resources.
Furthermore, Hugging Face offers an intuitive interface for interacting with its models directly through an interface window, like the “Playground” console window in OpenAI. However, this feature is available only for a select number of lightweight models that don’t demand much computational resources.
Here is one example of the gpt2 model in the HuggingFace interface, complete with its specifications and the accompanying console window.
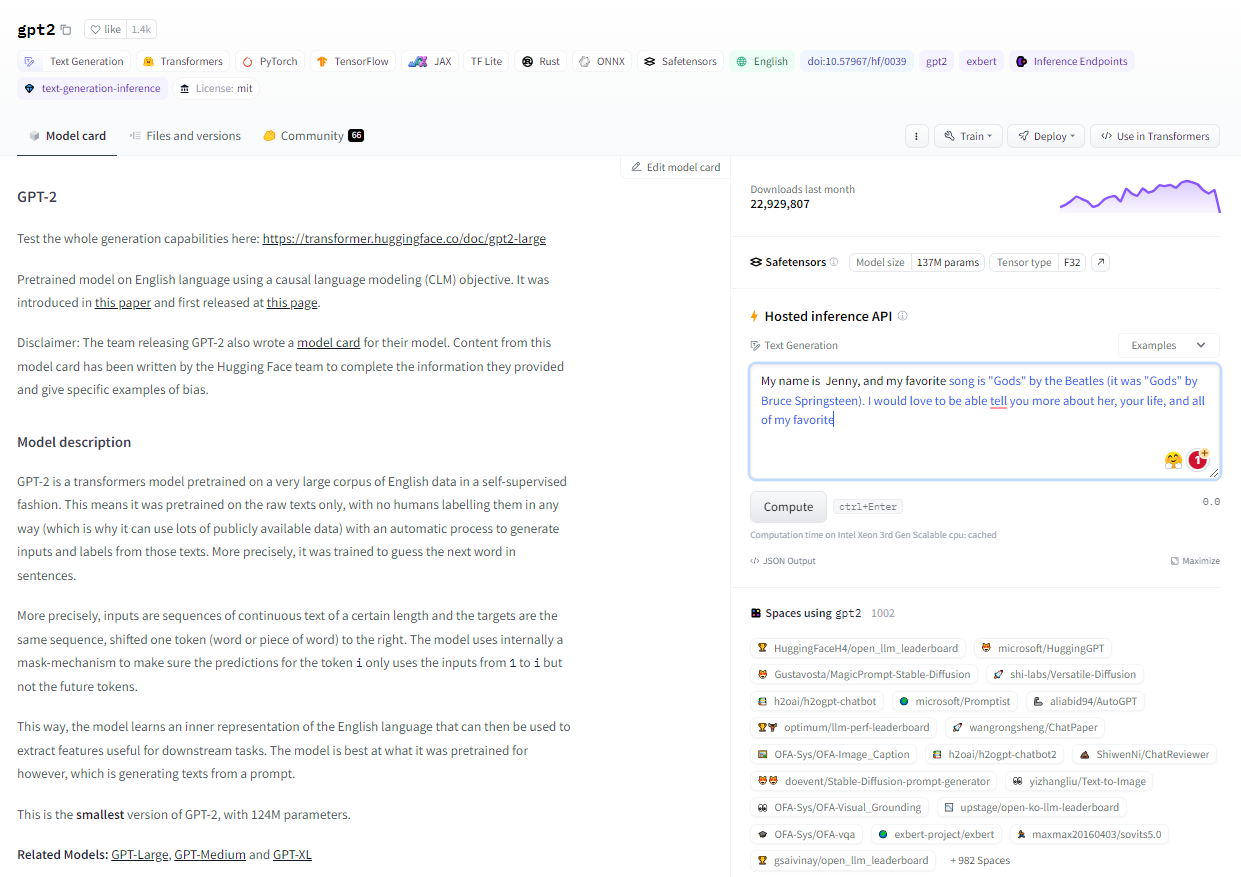 Specifications of the gpt2 model in HuggingFace
Specifications of the gpt2 model in HuggingFace
Within the Hugging Face platform, you can delve into and experiment with diverse models such as Google’s “flan-t5-base,”. In contrast, more computationally intensive models like “Llama2” require users to have their own GPU infrastructure to work with them effectively.
Choosing the Right Model
Yet, again, selecting the suitable model that fits your needs and provides the best resolution to the user is pivotal for the project’s success.
With plenty of models in the market, understanding the features of various models, experimenting with them, and having hands-on experience with them can help you mitigate the risks of deploying the wrong model and reduce costs instead of relying on a trial-and-error approach.
By understanding the essential factors to look for in a model and with enough hands-on experience with a particular model, you could choose an ideal fit for your use case and ensure it meets the objectives, which helps maximize the success of your endeavors in the AI landscape.
Are you interested to know more about the possibilities of AI in test and measurement? Click here and navigate to our “Blogs” section and find more similar blogs on AI in Test and Measurement.